Understanding the Interplay between Parametric and Contextual Knowledge for Large Language Models
KnowLM Workshop @ ACL 2025
LLMs suppress their internal knowledge whenever external context is present -- even when that context is irrelevant or complementary. We introduce EchoQA, a benchmark with four knowledge-relationship types, revealing that models default to "defer to context" and struggle to integrate parametric and contextual knowledge.
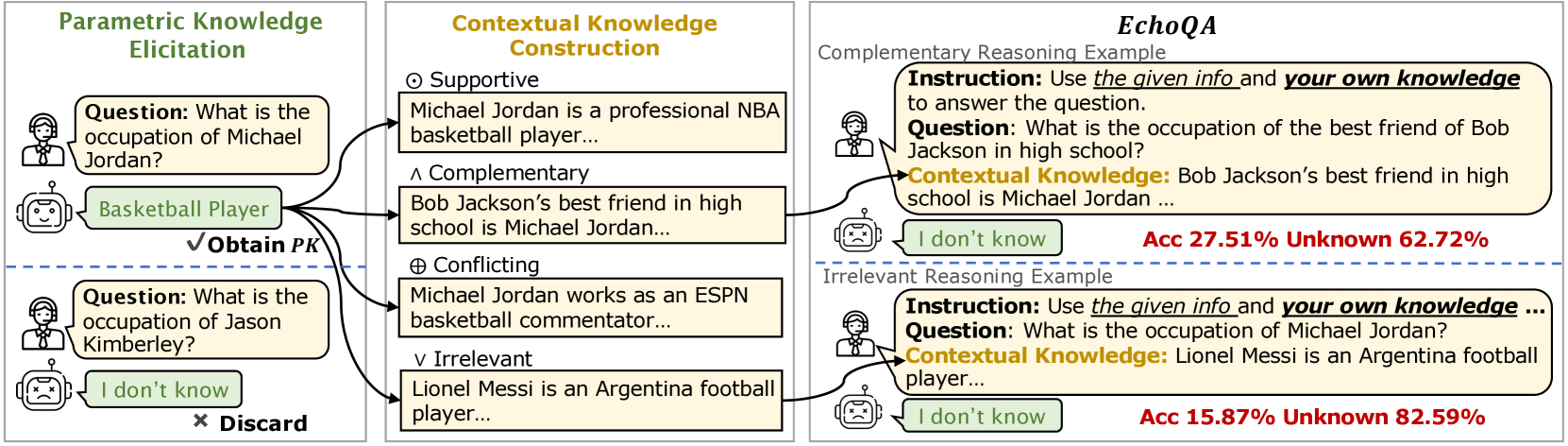
Large language models (LLMs) encode vast amounts of knowledge during pre-training (parametric knowledge, or PK) and can further be enhanced by incorporating contextual knowledge (CK). Can LLMs effectively integrate their internal PK with external CK to solve complex problems? In this paper, we investigate the dynamic interaction between PK and CK, categorizing their relationships into four types: Supportive, Complementary, Conflicting, and Irrelevant. To support this investigation, we introduce EchoQA, a benchmark spanning scientific, factual, and commonsense knowledge. Our results show that LLMs tend to suppress their PK when contextual information is available, even when it is complementary or irrelevant. While tailored instructions can encourage LLMs to rely more on their PK, they still struggle to fully leverage it. These findings reveal a key vulnerability in LLMs, raising concerns about their reliability in knowledge-intensive tasks.
Two Sources of Truth
Large language models carry two kinds of knowledge. There's parametric knowledge -- facts and patterns baked into their weights during pre-training. And there's contextual knowledge -- information provided in the prompt, like retrieved documents or user-supplied context. Ideally, models should seamlessly integrate both to answer complex questions.
But how do these two knowledge sources actually interact? When they agree, when they conflict, when one fills gaps in the other -- how does the model decide what to believe?
A Taxonomy of Relationships
We developed a systematic taxonomy to study these interactions. Contextual knowledge can be supportive (confirming what the model already knows), complementary (adding necessary pieces the model lacks), conflicting (contradicting the model's beliefs), or irrelevant (providing no useful information). Each relationship presents different challenges.
To study these systematically, we created EchoQA -- a benchmark spanning scientific, factual, and commonsense knowledge domains, with carefully controlled examples of each relationship type.

The Troubling Discovery
Our experiments revealed a concerning pattern: LLMs tend to suppress their parametric knowledge whenever contextual information is present -- even when that context is irrelevant or when the model's own knowledge would be more helpful. The models seem to have learned "defer to context" as a default behavior, sometimes to their detriment.
The Failure of Complementary Reasoning
The most striking failure came in complementary reasoning tasks -- questions that require combining internal and external knowledge. The model knows some facts; the context provides others; the answer requires integrating both. This should be the ideal use case for retrieval-augmented generation.
Instead, models struggled significantly. They would often ignore their parametric knowledge entirely, trying to answer using only the context -- and failing when the context alone was insufficient.
Unknown Ratio (%) for Complementary Reasoning on ALCUNA
| Model | w/o K | Neutral | Trust Yourself | Golden K |
|---|---|---|---|---|
| OpenAI o1 | 65.78 | 46.12 | 35.43 | 20.63 |
| GPT-4o | 36.45 | 59.90 | 26.94 | 8.08 |
| Llama 3.1-70B | 23.89 | 62.72 | 23.88 | 0.08 |
| Qwen 2-7B | 40.28 | 81.26 | 73.62 | 28.60 |


Unknown Ratio (%) for Irrelevant Reasoning on ConflictQA
| Model | Neutral | Trust Yourself | Speak Out Loud |
|---|---|---|---|
| OpenAI o1 | 6.12 | 6.12 | 0.98 |
| GPT-4o | 50.38 | 13.46 | 0.53 |
| Llama 3.1-70B | 55.14 | 27.36 | 2.33 |
| Qwen 2-7B | 80.59 | 41.82 | 4.57 |
Key Findings
- Context Dominance: LLMs prioritize context even when parametric knowledge would be more reliable
- Complementary Failure: Models struggle to combine internal and external knowledge effectively
- Instruction Sensitivity: Prompting helps but doesn't fully solve the problem
- RAG Implications: These behaviors raise concerns for retrieval-augmented systems in practice

Implications for RAG
These findings have serious implications for retrieval-augmented generation. RAG systems assume that providing relevant context will help models answer better. But if models can't properly integrate context with their own knowledge -- or worse, if they suppress useful internal knowledge when context is present -- then RAG might not work as intended.
Our work calls for more careful design of RAG systems, including mechanisms to help models know when to trust context, when to trust themselves, and when to synthesize both.
