Differentiable Evolutionary Reinforcement Learning
ArXiv Preprint 2025
DERL makes reward function design differentiable by evolving structured reward primitives with meta-gradients, enabling autonomous discovery of optimal reward signals that achieve state-of-the-art on robotic, scientific, and mathematical reasoning tasks.
The design of effective reward functions presents a central and often arduous challenge in reinforcement learning (RL), particularly when developing autonomous agents for complex reasoning tasks. While automated reward optimization approaches exist, they typically rely on derivative-free evolutionary heuristics that treat the reward function as a black box, failing to capture the causal relationship between reward structure and task performance. To bridge this gap, we propose Differentiable Evolutionary Reinforcement Learning (DERL), a bi-level framework that enables the autonomous discovery of optimal reward signals. In DERL, a Meta-Optimizer evolves a reward function (i.e., Meta-Reward) by composing structured atomic primitives, guiding the training of an inner-loop policy. Crucially, unlike previous evolution, DERL is differentiable in its meta-optimization: it treats the inner-loop validation performance as a signal to update the Meta-Optimizer via reinforcement learning. This allows DERL to approximate the "meta-gradient" of task success, progressively learning to generate denser and more actionable feedback. We validate DERL across three distinct domains: robotic agent (ALFWorld), scientific simulation (ScienceWorld), and mathematical reasoning (GSM8k, MATH). Experimental results show that DERL achieves state-of-the-art performance on ALFWorld and ScienceWorld, significantly outperforming methods relying on heuristic rewards, especially in out-of-distribution scenarios. Analysis of the evolutionary trajectory demonstrates that DERL successfully captures the intrinsic structure of tasks, enabling self-improving agent alignment without human intervention.
The Reward Design Problem
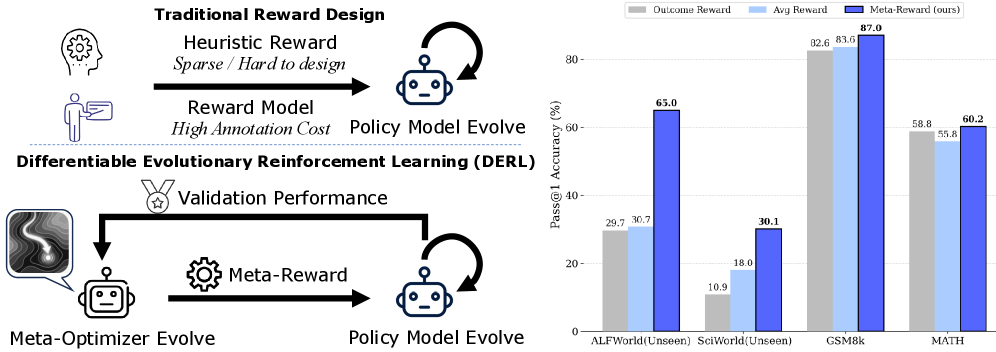
Reinforcement learning has a dirty secret: the hardest part isn't the algorithm -- it's the reward function. Getting the reward right often requires extensive trial and error, domain expertise, and sometimes luck. A poorly designed reward leads to agents that technically optimize what you asked for but not what you actually wanted.
Existing approaches to automatic reward design treat the reward function as a black box, using evolutionary heuristics to search for better rewards. But evolution is slow and inefficient -- it can't see the causal relationship between reward structure and task performance.
How DERL Works
DERL bridges this gap with a key insight: what if we could make the evolutionary process differentiable? Instead of blind mutation and selection, what if we could compute gradients that tell us exactly how to improve the reward function?
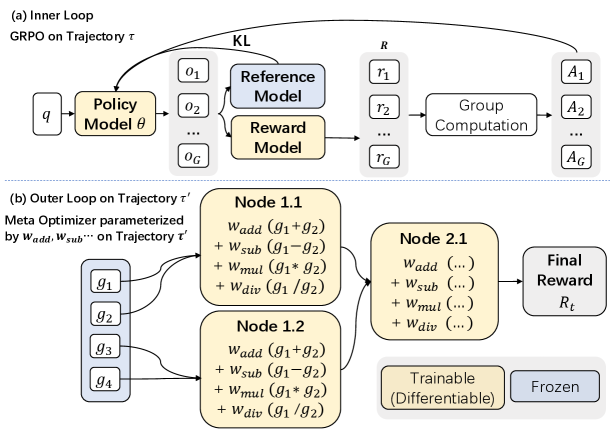
Compose Structured Rewards
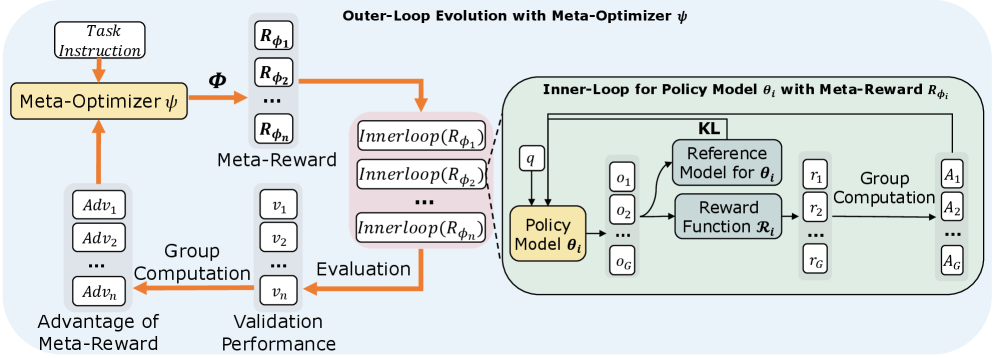
The Meta-Optimizer generates reward functions by composing structured atomic primitives into computational graphs, producing a parameterized Meta-Reward.
Train Inner-Loop Policy
An inner-loop policy is trained using GRPO with the generated Meta-Reward, learning to solve tasks guided by the evolved reward signal.
Evaluate on Validation
The trained policy is evaluated on a held-out validation set. This validation performance serves as the learning signal for the Meta-Optimizer.
Update via Meta-Gradient
The Meta-Optimizer is updated through reinforcement learning, approximating the meta-gradient of task success with respect to reward structure -- making evolution differentiable.
The Technical Innovation
DERL approximates the meta-gradient of task success with respect to reward structure. This allows it to progressively learn to generate denser, more actionable feedback. Unlike black-box evolution, DERL understands why certain reward functions work better and can generalize this understanding to design better rewards.
From Robots to Math
We validated DERL across three distinct domains that test different aspects of reward design. In ALFWorld, robotic agents must navigate and manipulate objects in household environments. In ScienceWorld, agents conduct scientific experiments in simulation. In GSM8K and MATH, agents solve mathematical reasoning problems.
Across all domains, DERL discovers reward functions that outperform hand-designed baselines -- without any domain-specific engineering of the rewards themselves.
ALFWorld & ScienceWorld Performance
| Method | ALFWorld L0 | ALFWorld L1 | ALFWorld L2 | SciWorld L0 | SciWorld L1 | SciWorld L2 |
|---|---|---|---|---|---|---|
| GRPO w/ Outcome | 76.6 | 71.1 | 29.7 | 21.1 | 13.7 | 10.9 |
| GRPO w/ Avg Reward | 88.1 | 85.4 | 30.5 | 37.9 | 31.3 | 18.0 |
| GiGPO | 86.7 | 83.2 | 48.0 | 25.8 | 15.2 | 4.7 |
| RLVMR | 89.1 | 87.9 | 56.3 | 46.9 | 34.4 | 26.5 |
| DERL | 91.0 | 89.1 | 65.0 | 47.7 | 43.0 | 30.1 |
| DERL-pop. | 91.8 | 88.3 | 76.4 | 98.2 | 95.3 | 31.3 |
Mathematical Reasoning Performance (GSM8K & MATH)
| Reward Function | Training Data | GSM8K | MATH |
|---|---|---|---|
| Outcome | MATH+GSM8K | 82.6 | 58.8 |
| Outcome + Format | MATH+GSM8K | 86.4 | 55.9 |
| Avg Reward | MATH+GSM8K | 86.5 | 55.8 |
| Outcome | MATH | 82.9 | 59.1 |
| Outcome + Format | MATH | 83.9 | 56.8 |
| Avg Reward | MATH | 83.6 | 54.9 |
| DERL | MATH+GSM8K | 87.0 | 60.2 |
| DERL-pop. | MATH+GSM8K | 87.6 | 60.2 |
| DERL | MATH | 83.2 | 60.5 |
| DERL-pop. | MATH | 84.1 | 60.9 |
Key Results
- ALFWorld: Improved robotic task completion through learned reward shaping, with DERL-pop. reaching 76.4% on the hardest L2 split (vs. 56.3% for RLVMR)
- ScienceWorld: Dramatic improvement in scientific reasoning -- 98.2% on L0 (vs. 46.9% for RLVMR)
- GSM8K & MATH: Enhanced mathematical reasoning through meta-learned rewards, achieving 87.6% and 60.9% respectively
- Generalization: Strongest gains in out-of-distribution scenarios where heuristic rewards prove less effective

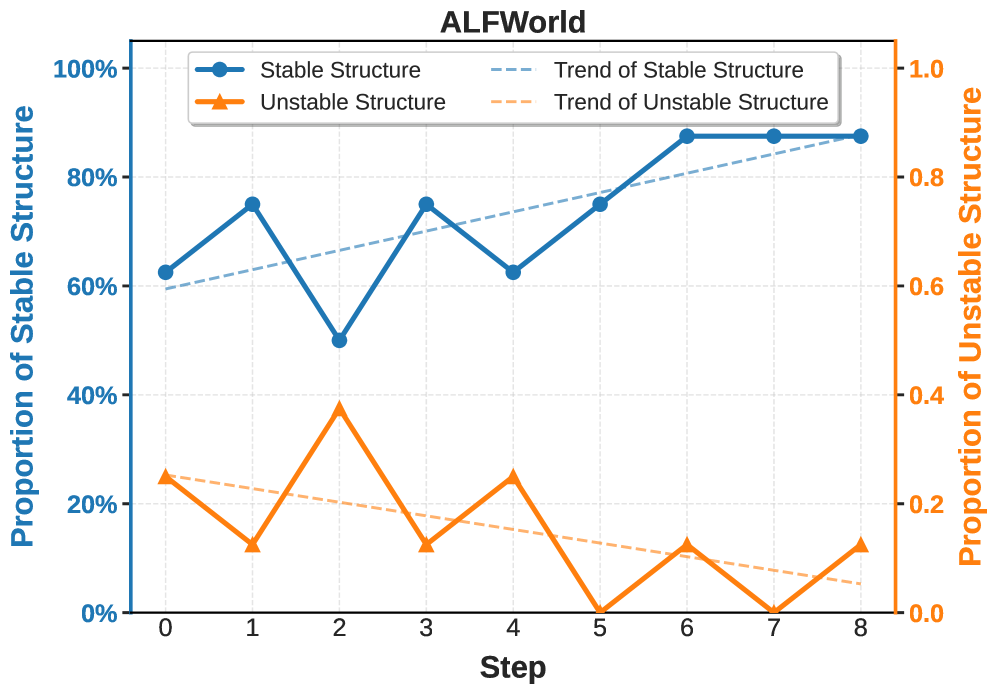
Evolution of Reward Structures
Analysis of the evolutionary trajectory reveals that DERL learns to progressively favor mathematically robust reward structures. Over the course of training, the proportion of stable reward primitives increases while unstable ones are naturally selected against -- the system discovers not just good rewards, but structurally sound ones.
Toward Autonomous Reward Design
DERL represents a step toward truly autonomous reinforcement learning -- systems that can design their own training signals without human intervention. By making the reward design process differentiable, we open the door to more efficient and effective automatic curriculum design, where agents learn not just to solve tasks but to teach themselves how to learn.