COrAL: Order-Agnostic Language Modeling for Efficient Iterative Refinement
ArXiv Preprint 2024
COrAL breaks the left-to-right bottleneck in language models by enabling order-agnostic generation within local windows, achieving up to 3.9x inference speedup and +4.6% accuracy on GSM8K through built-in iterative refinement.
Iterative refinement has emerged as an effective paradigm for enhancing the capabilities of large language models (LLMs) on complex tasks. However, existing approaches face a critical trade-off between output quality and computational efficiency due to their reliance on autoregressive (left-to-right) generation. We introduce COrAL (Context-wise Order-Agnostic Language Modeling), which embeds iterative refinement directly into the language model architecture. Our approach employs sliding blockwise order-agnostic decoding, which performs multi-token forward prediction and backward reconstruction within context windows. On reasoning benchmarks, COrAL achieves absolute accuracy gains of 4.6% on GSM8K and 4.0% on LogiQA, along with inference speedups of up to 3.9x over next-token baselines. However, code generation tasks reveal performance degradation due to output inconsistencies, highlighting inherent quality-speed trade-offs in order-agnostic generation.
Breaking the Sequential Bottleneck
Language models generate text one token at a time, left to right. This sequential constraint is so fundamental that we rarely question it. But it comes with a cost: every token must wait for all previous tokens, making iterative refinement -- where models reconsider and improve their outputs -- painfully slow.
What if we could break free from strict left-to-right generation? What if a model could refine multiple positions simultaneously, reasoning about dependencies without the sequential bottleneck?
Order-Agnostic Modeling
COrAL introduces a fundamentally different approach: Context-wise Order-Agnostic Language Modeling. Instead of predicting only the next token, COrAL models multiple token dependencies within manageable context windows. This allows the model to generate and refine tokens in parallel, capturing diverse dependencies without strict ordering.
The key insight is that within a local window, the "correct" order of generation is not always clear -- and enforcing one might actually hurt performance. By being agnostic to order, COrAL can choose the most informative generation sequence dynamically.
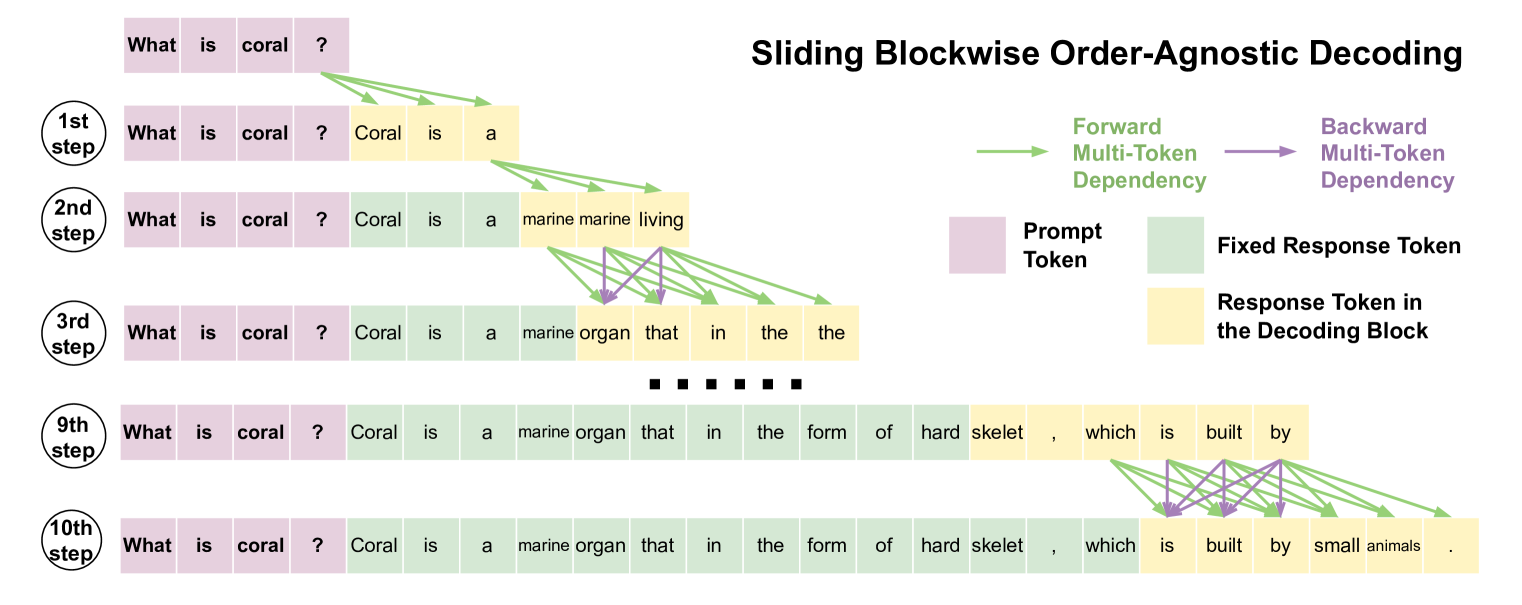
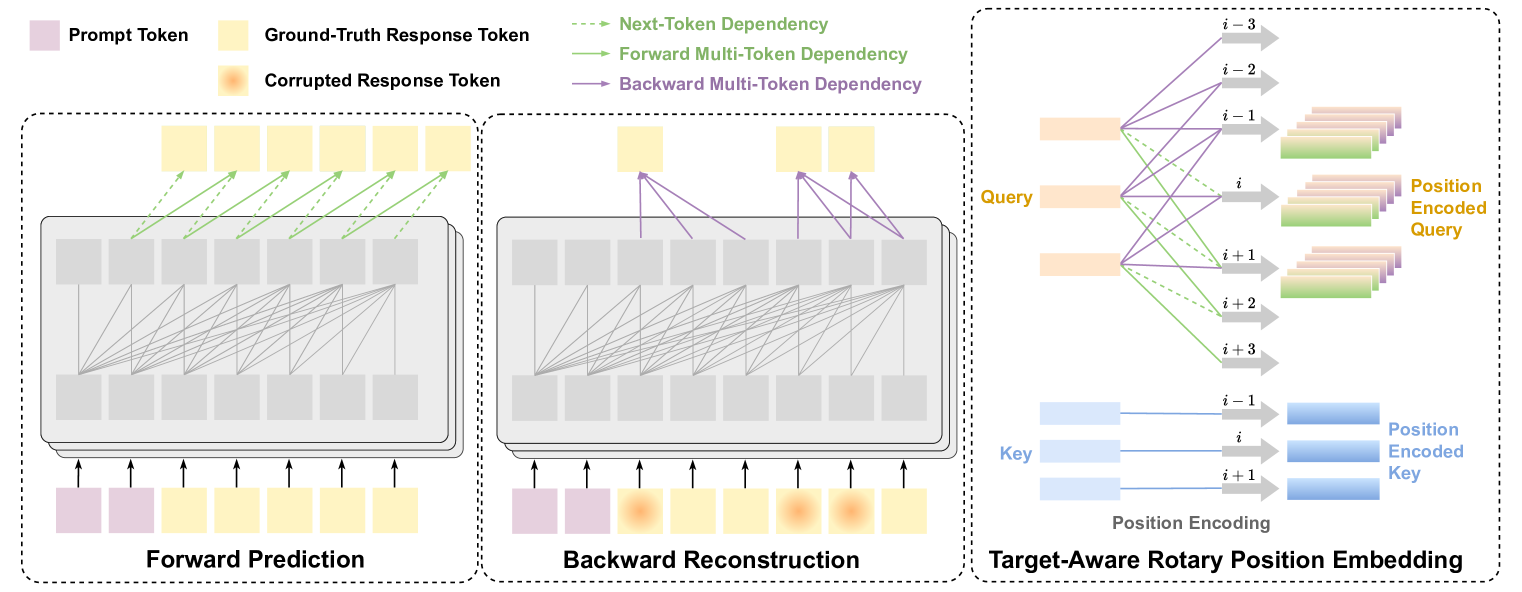
The Technical Innovation
We introduce sliding blockwise order-agnostic decoding. The model predicts multiple tokens forward, then reconstructs backward within each window. As the window slides, the model iteratively refines its outputs -- all happening in parallel within each block. This achieves the benefits of iterative refinement without the sequential cost.
Built Into the Architecture
Previous approaches to iterative refinement operated at the prompting or application level -- asking models to "think again" or "check your work." COrAL incorporates refinement directly into the architecture. The model does not need to be told to reconsider; it naturally refines as part of its generation process.
This architectural integration means refinement happens efficiently, without the overhead of multiple forward passes or explicit self-correction prompts.
Arithmetic Reasoning (GSM8K & MATH)
| Approach | GSM8K Acc. | GSM8K Speed | Speedup | MATH Acc. | MATH Speed | Speedup |
|---|---|---|---|---|---|---|
| NT (baseline) | 74.1% | 39.7 | 1.0x | 21.8% | 38.7 | 1.0x |
| COrAL (full) | 75.3% | 43.4 | 1.1x | 22.7% | 44.4 | 1.1x |
| COrAL w/o verifier | 72.4% | 156.8 | 3.9x | 20.0% | 139.7 | 3.6x |
| COrAL w/o multi-forward | 78.7% | 14.9 | -- | 24.3% | 11.5 | -- |
Logical Reasoning (LogiQA & ReClor)
| Approach | LogiQA Acc. | Speed | Speedup | ReClor Acc. | Speed | Speedup |
|---|---|---|---|---|---|---|
| NT (baseline) | 55.1% | 33.6 | 1.0x | 63.2% | 33.2 | 1.0x |
| COrAL (full) | 58.2% | 62.1 | 1.8x | 62.7% | 38.2 | 1.2x |
| COrAL w/o verifier | 55.7% | 99.1 | 2.9x | 61.6% | 72.0 | 2.2x |
| COrAL w/o multi-forward | 59.1% | 8.9 | -- | 64.7% | 11.3 | -- |
Key Results
- Efficiency Gains: Parallel generation within blocks achieves up to 3.9x inference speedup
- Better Reasoning: +4.6% absolute accuracy on GSM8K and +4.0% on LogiQA
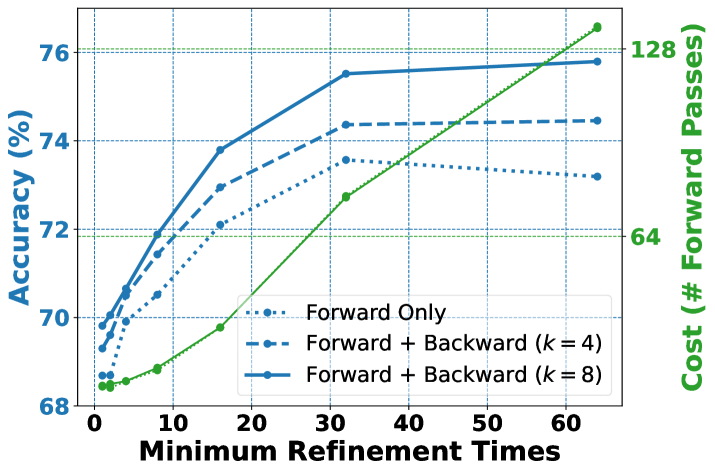
- Scalable Refinement: Performance improves with more refinement iterations
- Architectural Innovation: Refinement built into the model, not bolted on
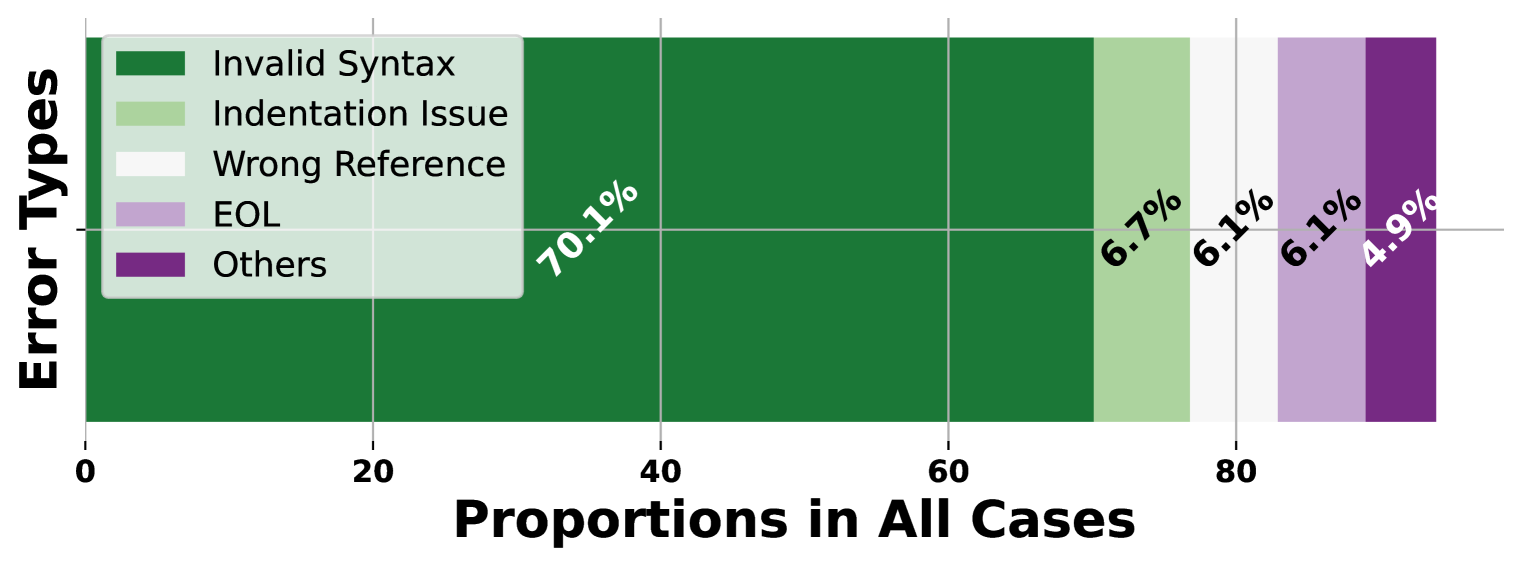
Trade-offs in Code Generation
While COrAL excels at reasoning tasks, code generation reveals an important limitation. Strict syntactic requirements in code are harder to satisfy with order-agnostic generation, with syntax errors accounting for 70.1% of failure cases. This highlights that the approach is best suited for tasks where token ordering is less rigid.
Looking Forward
COrAL challenges the assumption that autoregressive, left-to-right generation is the only way to build language models. By relaxing the ordering constraint within local windows, we unlock new possibilities for efficient iterative refinement -- a capability increasingly important as we push models toward more complex reasoning tasks.