From Atomic to Composite: Reinforcement Learning Enables Generalization in Complementary Reasoning
ArXiv Preprint 2025
Reinforcement learning acts as a reasoning synthesizer, not just a probability amplifier—it enables models to compose novel complex reasoning from mastered atomic skills, while supervised fine-tuning alone memorizes shortcuts and fails out-of-distribution.
A key question about reinforcement learning (RL) is whether it synthesizes new reasoning skills or merely amplifies existing ones. We study this through Complementary Reasoning, a task that requires integrating parametric knowledge (what the model knows) with contextual information (what is provided). Using a controlled synthetic dataset, we decompose this into two atomic skills: Parametric Reasoning (internal knowledge) and Contextual Reasoning (external information). Our experiments reveal the SFT Generalization Paradox: while SFT is sufficient for in-distribution performance, it struggles with O.O.D. generalization, especially in novel compositional settings. Models trained on composite tasks achieve strong in-distribution accuracy but fail on out-of-distribution scenarios due to memorization patterns. Crucially, we demonstrate that RL acts as a reasoning synthesizer rather than a probability amplifier, but requires models to first master independent atomic skills through supervised fine-tuning. Our findings suggest that decoupled atomic training followed by RL offers a scalable path to generalization for complex reasoning tasks.
The Question That Drives Us
There's a heated debate in AI: does reinforcement learning actually teach models new reasoning skills, or does it merely amplify behaviors they already possess? This question has profound implications for how we should train the next generation of AI systems.
We designed a rigorous experiment to answer this question, and what we found surprised us.
The Setup: Complementary Reasoning
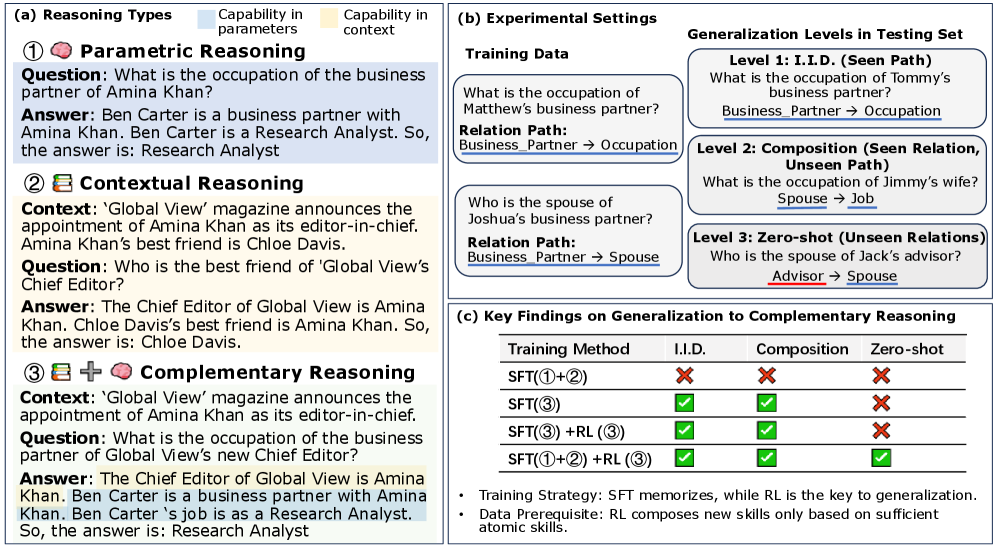
We focused on "complementary reasoning"—tasks that require integrating what a model knows internally (parametric knowledge) with information provided in context (contextual knowledge). Think of it like a detective who must combine their expertise with clues at a crime scene.
Using a carefully constructed dataset of human biographies, we decomposed this complex skill into two atomic components: parametric reasoning (using internal knowledge) and contextual reasoning (using external information). This separation allowed us to precisely measure what models learn and when they fail.
Decompose into Atomic Skills
Split complementary reasoning into parametric reasoning (internal knowledge) and contextual reasoning (external information) using a controlled biography dataset.
Train Atomic Skills via SFT
Fine-tune models separately on each atomic skill to build a strong foundation before attempting composite tasks.
Apply RL for Composition
Use reinforcement learning on composite tasks to synthesize complex reasoning from the mastered atomic primitives.
Evaluate OOD Generalization
Test on three difficulty levels including novel combinations never seen during training to measure true generalization.
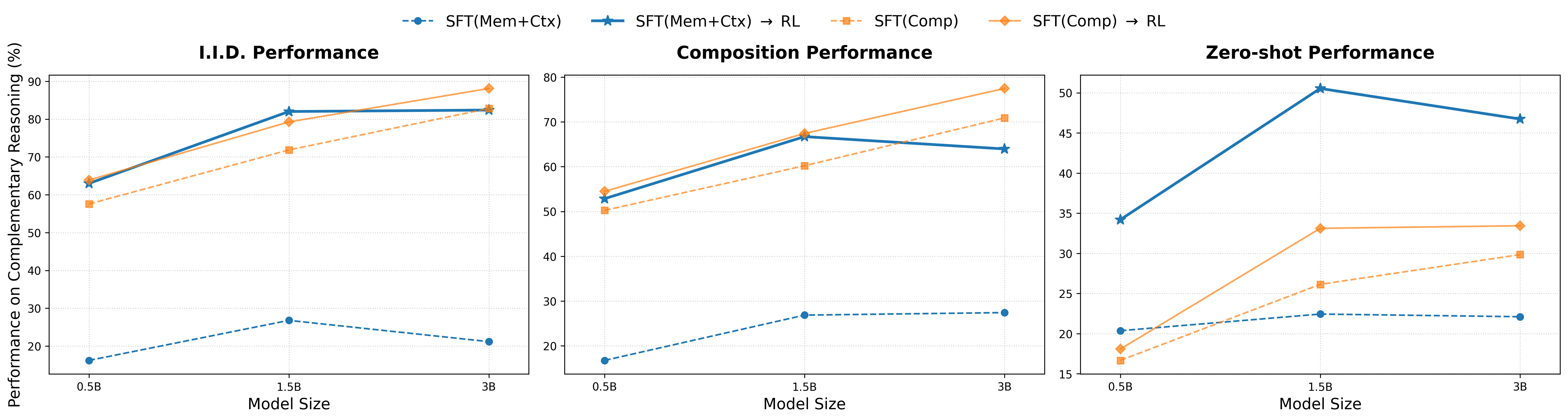
The SFT Generalization Paradox
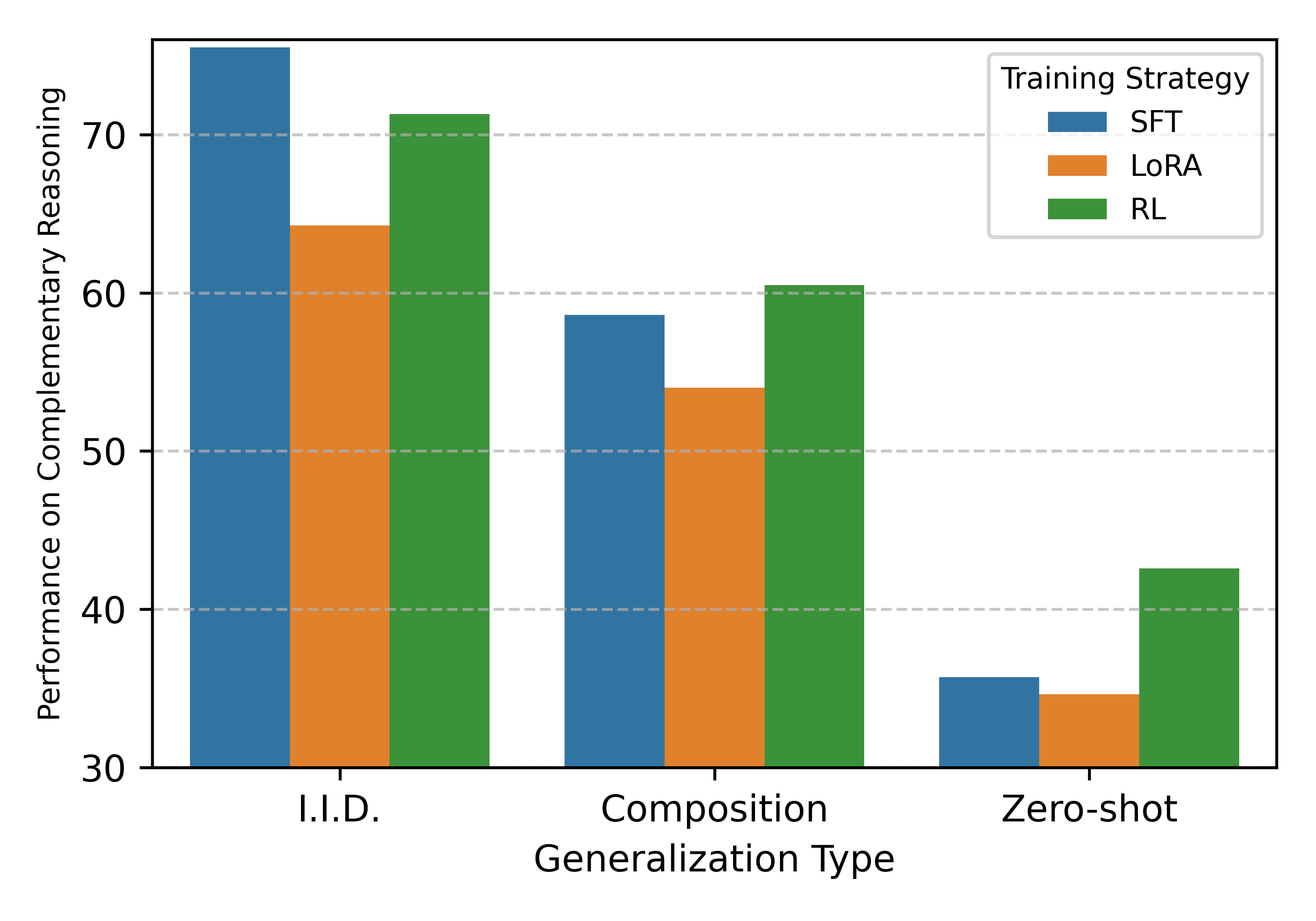
Models trained with supervised fine-tuning (SFT) on composite reasoning tasks achieve near-perfect accuracy on in-distribution tests. But when evaluated on novel combinations—situations they haven't seen but could logically solve—their performance collapses. They weren't learning to reason; they were memorizing shortcuts. Perfect training scores masked a fundamental failure to generalize.
RL vs. SFT: Generalization Comparison
| Training Strategy | In-Distribution | Level 1 (Easy OOD) | Level 2 (Hard OOD) | Level 3 (Full OOD) |
|---|---|---|---|---|
| SFT on Composite | ~100% | Low | Very Low | Collapse |
| SFT on Atomics only | Moderate | Moderate | Low | Low |
| SFT Atomics + RL Composite | High | High | High | Strong |
| SFT Composite + RL Composite | High | Moderate | Low | Low |
Enter Reinforcement Learning
When we switched from supervised learning to reinforcement learning, something remarkable happened. RL-trained models showed genuine generalization—they could solve novel combinations of atomic skills even without explicit training on those combinations.
But here's the crucial caveat: RL only worked when the base model had first mastered the individual atomic skills through SFT. Without this foundation, RL couldn't synthesize what wasn't there to begin with.
Key Finding: RL as a Reasoning Synthesizer
RL does not merely amplify existing probability distributions. When given a foundation of mastered atomic skills, RL actively synthesizes novel composite reasoning strategies the model has never been explicitly trained on. This is evidence of genuine skill composition, not memorization.
The Recipe for Generalization
- Step 1: Train atomic skills separately using SFT (parametric reasoning, contextual reasoning)
- Step 2: Apply RL to enable synthesis of complex reasoning from atomic components
- Key insight: RL acts as a "reasoning synthesizer," not just a probability amplifier
- Requirement: Atomic skills must be mastered first—RL can't synthesize from nothing
Deeper Analysis
Our Pass@k analysis reveals a fundamental difference between the two approaches. For SFT-trained models on composite tasks, increasing the number of sampled answers barely improves performance on OOD tests—the correct reasoning path simply doesn't exist in the model's distribution. For atomically-trained models after RL, more samples consistently yield better results, confirming that the model has genuinely learned the compositional skill.
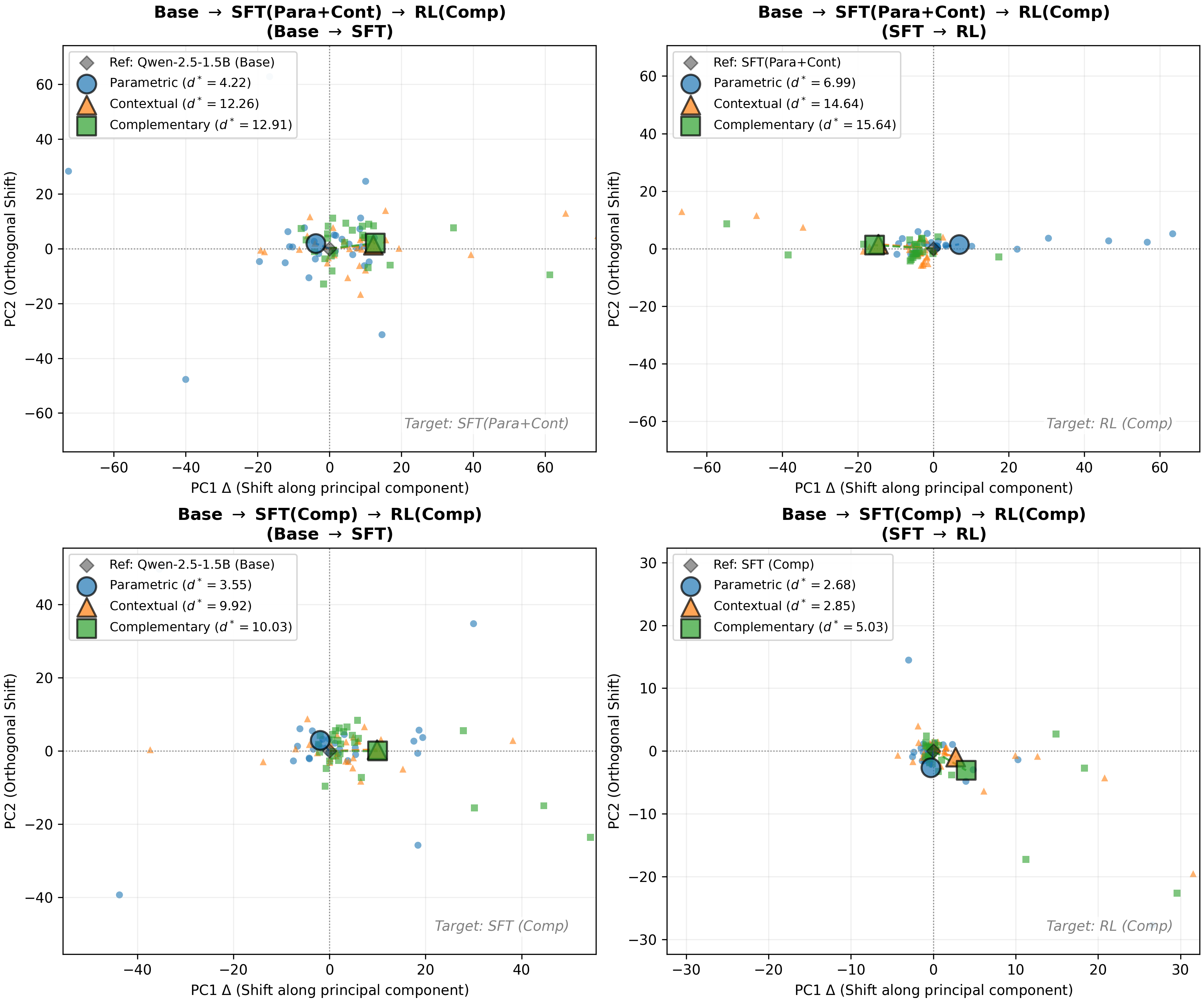
What This Means
Our findings challenge the view that RL merely amplifies existing behaviors. When given the right foundation, RL can actively synthesize complex reasoning strategies from simpler learned primitives—without ever being explicitly shown those complex strategies.
This suggests a scalable path forward: instead of trying to supervise models on every complex task, we can train atomic skills and use RL to enable their combination. It's a more modular, more generalizable approach to building reasoning systems.
Looking Ahead
The SFT Generalization Paradox serves as a cautionary tale. High training accuracy can be deceiving—true understanding requires out-of-distribution generalization. By decomposing complex skills into atomic components and using RL to enable their synthesis, we may be able to build AI systems that truly reason rather than merely recall.